Помимо того, сайта, важно знать, как правильно его применить с максимальной пользой для внутренней и внешней оптимизации сайта.
Уже очень много статей написано на тему того как сделать семантическое ядро, поэтому, в рамках данной статьи, я хочу обратить Ваше внимание на некоторые особенности и детали, которые помогут Вам правильно использовать семантическое ядро, и тем самым, помочь раскрутить интернет-магазин или сайт. Но сперва, вкратце дам свое определение семантическому ядру сайта.
Что такое семантическое ядро сайта?
Семантическое ядро сайта - это список, набор, массив, совокупность ключевых слов и фраз, которые запрашиваются пользователями (Вашими потенциальными посетителями) в браузерах поисковых систем, чтобы найти интересующую информацию.
Зачем нужно веб-мастеру составлять семантическое ядро?
Исходя из определения семантического ядра, возникает масса очевидных ответов на этот вопрос.
Владельцам интернет-магазинов важно знать, каким образом потенциальные покупатели пытаются найти тот товар или услугу, которую владелец интернет-магазина желает продать или предоставить. От этого понимания напрямую зависит положение интернет-магазина в поисковой выдаче. Чем более соответствует наполнение интернет-магазина покупательским поисковым запросам - тем ближе интернет-магазин к ТОПу поисковой выдачи. А значит, конверсия посетителей в покупатели будет выше и качественнее.
Для блоггеров, которые активно занимаются монетизацией своих блогов (манимейкингом), также важно быть в ТОПе поисковой выдачи по тематике релевантной содержанию блога. Увеличение поискового трафика несет больше прибыли от показов и кликов из контекстной рекламы на сайте, показов и кликов по рекламным блокам партнёрских программ и рост прибыли по другим видам заработка.
Чем больше на сайте оригинального и полезного контента - тем ближе сайт к ТОПу. Жизнь существует преимущественно на первой странице выдачи поисковых систем. Поэтому, знание того как сделать семантическое ядро является необходимым для SEO любого сайта, интернет-магазина.
Иногда веб-мастера и владельцы интернет-магазинов задаются вопросом - где брать качественный и релевантный контент? Ответ исходит из вопроса - нужно создавать контент в соответствии с ключевыми запросами пользователей. Чем больше поисковые системы будут считать контент Вашего сайта релевантным (подходящим) ключевым словам пользователей - тем лучше для Вас. Кстати, отсюда возникает ответ на вопрос - где брать разнообразие тематики контента? Всё просто - анализируя поисковые запросы пользователей, можно узнать чем они интересуются и в какой форме. Таким образом, сделав семантическое ядро сайта, можно написать ряд статей и/или описаний для товаров интернет-магазина, оптимизируя каждую страницу для определенного ключевого слова (поискового запроса).
К примеру, данную статью я решил оптимизировать по ключевому запросу "как сделать семантическое ядро", потому что конкуренция по данному запросу ниже, чем по запросу "как создать семантическое ядро" или "как составить семантическое ядро". Таким образом, мне гораздо легче пробиться к ТОПу выдачи поисковых систем по этому запросу абсолютно бесплатными методами раскрутки.
Как сделать семантическое ядро, с чего начать?
Для составления семантического ядра существует ряд популярных он-лайн сервисов.
Самым популярным сервисом, на мой взгляд, является статистика ключевых слов Яндекса - http://wordstat.yandex.ru/
При помощи данного сервиса можно собрать подавляющее большинство поисковых запросов в различных словоформах и комбинациях для любой тематики. Например, в левой колонке мы видим статистику количества запросов не только по ключевой фразе "семантическое ядро", но и статистику по различным комбинациям данной ключевой фразы в разных спряжениях и с разбавочными и дополнительными словами. В левой колонке мы видим статистику поисковых фраз, которые искали вместе с ключевой фразой "семантическое ядро". Эта информация может быть ценной, хотя бы в качестве источника тем для создания нового, релевантного Вашему сайту, контента. Ещё хочу упомянуть одну особенность этого сервиса - Вы можете уточнить регион. Благодаря этой опции Вы можете более точно узнать количество и характер нужных Вам поисковых запросов по нужному региону.

Ещё одним сервисом для составления семантического ядра является статистика поисковых запросов рамблера - http://adstat.rambler.ru/

На мой субъективный взгляд, данным сервисом можно пользоваться в том случае, когда идёт битва за привлечение на свой сайт каждого единичного пользователя. Здесь можно уточнить некоторые низкочастотные и long tail запросы, обращение пользователей по ним составляет приблизительно от 1 до 5-10 в месяц, т.е. очень мало. Сразу же оговорюсь, что в дальнейшем мы рассмотрим тему классификации ключевых слов и особенности каждой группы с точки зрения их применения. Поэтому, лично я крайне редко пользуюсь данной статистикой, как правило в тех случаях, если я занимаюсь или узкоспециализированного сайта.
Для формирования семантического ядра сайта также можно пользоваться подсказками, которые выпадают при вводе поискового запроса в браузере поисковика.


И ещё один вариант для жителей Украины пополнить список ключевых слов для семантического ядра сайта - просмотреть статистику сайтов на - http://top.bigmir.net/

Выбрав нужную тематику раздела, ищем открытую статистику наиболее посещаемого и подходящего по тематике сайта

Как видите, интересующая статистика не всегда может быть открытой, как правило, веб-мастера скрывают её. Тем не менее, в качестве дополнительного источника ключевых слов тоже может сгодиться.
Кстати, о том как оформить красиво в табличном виде в Excel весь список ключевых слов Вас научит замечательная статья Глобатора (Михаила Шакина) - http://shakin.ru/seo/keyword-suggestion.html Там же можно прочесть о том как сделать семантическое ядро для англоязычных проектов.
Что делать дальше со списком ключевых слов?
В первую очередь чтобы сделать семантическое ядро, я рекомендую структурировать список ключевых слов - разбить его на условные группы: на высокочастотные (ВЧ), среднечастотные (СЧ) и назкочастотные (НЧ) ключевые слова. Важно, чтобы в данные группы попадали ключевые слова очень близкие по морфологии и тематике. Сделать это удобнее всего в виде таблицы. Я это делаю приблизительно так:

Верхняя строка таблицы - это высокочастотные (ВЧ) поисковые запросы (написаны красным). Их я поставил во главе тематических колонок, в каждую ячейку которых я отсортировал среднечастотные (СЧ) и низкочастотные (НЧ) поисковые запросы максимально однородно по тематике. Т.е. к каждому ВЧ запросу я привязал наиболее подходящие группы СЧ и НЧ запросов. Каждая ячейка СЧ и НЧ запросов - это будущая статья, которую я пишу и оптимизирую строго под набор ключевых слов в ячейке. В идеале, одна статья должна соответствовать одному ключевому слову (поисковому запросу), но это очень рутинная и затратная по времени работа, ведь таких ключевых слов могут быть тысячи! Поэтому, если их очень много, нужно выделить для себя самые значимые, а остальные отсеять. Также, можно оптимизировать будущую статью под 2 - 4 СЧ и НЧ ключевых слова.
Для интернет-магазинов, СЧ и НЧ поисковые запросы как правило, являются названиями товаров. Поэтому, здесь не возникает особых трудностей внутренняя оптимизация каждой страницы интернет-магазина, просто это длительный процесс. Он тем дольше, чем больше товаров в интернет-магазине.
Зеленым цветом я выделил те ячейки, на которые у меня уже готовы статьи, т.о. я в дальнейшем не запутаюсь со списком готовых статей.
О том как нужно оптимизировать и писать статьи для сайта я расскажу в одной из будущих статей.
Итак, сделав такую таблицу, Вы можете иметь весьма четкое представление о том, как можно сделать семантическое ядро сайта.
В итоге данной статьи, хочу сказать, что здесь мы в какой-то степени коснулись детализации вопроса о раскрутке интернет-магазина . Наверняка, прочитав некоторые мои статьи о раскрутке интернет-магазина Вам пришла мысль о том, что составление семантического ядра сайта и внутренняя оптимизация являются взаимосвязанными и взаимозависящими мероприятиями. Я надеюсь, что смог аргументировать важность и первоочередность вопроса - как сделать семантическое ядро сайта.
Сами запросы можно разделить на три группы:
- Первичные запросы характеризуют сайт в общем. К примеру, для моего сайта: заработок на дому, заработок в интернете, работа в интернете.
- Основные запросы входят в семантическое ядро и по ним стоит продвигать сайт. К примеру: заработок в интернете без вложений, работа в интернете для мам.
- Вспомогательные запросы или ассоциативные, т.е. схожие по смыслу с основными. Например, кем работать в декрете, подработка для мамы в декрете.
Составляем семантическое ядро своими руками онлайн
wordstat.yandex.ru самый доступный способ для создания СЯ. На этом сайте показывается, сколько раз в месяц люди вбивают в поиск ту или иную фразу (ключевой запрос).
Работать довольно просто – в главное поле введите первичный запрос, который охарактеризует сайт в целом или нужную страницу/раздел сайта. К примеру «заработок в интернете».
Слева вы получите список основных запросов (заработок в интернете без вложений) и вспомогательных (заработок в сети, дополнительный доход).
Имейте в виду, что данные цифры показывают сколько раз встречался данный запрос, но не конкретно в таком виде. Так, к примеру, люди искали не «заработок без вложений», а «заработок в интернете без вложений», «заработок денег без вложений» и т.п.
Чтобы понять, сколько раз люди искали конкретную фразу, нужно взять ее в кавычки и поставить в начале восклицательный знак: «!заработок без вложений». Значение стало в несколько раз меньше, но теперь вы знаете точную частотность, т.е. сколько людей вбивают в поиск конкретно эту фразу.
Аналогичным образом происходит подбор ключевых запросов для гугла (Google.Adwords) и рамблера (Rambler.Adstat). Остальные поисковые системы слишком незначительные, чтобы подбирать под них запросы.
Но согласитесь, вручную подбирать все эти запросы очень сложно, муторно и долго. Поэтому лучше воспользоваться программами.
Составляем семантическое ядро: программы
- На верхней панели нажмите на шестеренку и зайдите в настройки. Здесь много всего можно подстроить под себя, но сейчас перейдите в последнюю вкладку Yandex.Direct;
- Введите логин и пароль от Яндекса (создайте доп.ящик, т.к. его могут забанить);
- Жмите создать новый проект, назовите и сохраните его;
- Нажмите на «Пакетный сбор слов из левой колонки Yandex Wordstat»;
- Внесите первичный запрос и пару основных, затем жмите Начать сбор;
- Просмотрите выдачу и пометьте галочкой все, которые не подходят для вас, потом кликните правой кнопкой мыши и Удалить отмеченные строки;
- Нажмите «Сбор частотности из сервиса Yandex.Wordstat» — Собрать частотности «!».
- Ориентируйтесь именно на столбец «Частотность «!»» — это конкретное число запросов именно этой фразы (в месяц). Можно отфильтровать по возрастанию, и сразу отбросить все КЗ с частотностью ниже 30 — это всего 1 запрос в день.
- Экспортируйте данные в Excel – нажмите на верхней панели соответствующий значок.
– платная программа (около 1700 рублей). С ним работают профессиональные сеошники. Если вы хотите просто подобрать СЯ для небольшого блога и все, не стоит платить такие деньги за программу, лучше использовать Словоеб. Чаще всего ее покупают опытные блоггеры со множеством сайтов или веб-райтеры, занимающиеся сео-статьями.
Работать с программой очень просто:
- Начать новый проект;
- Выбрать регион Россия + СНГ (или другое);
- Введите поисковый запрос и нажмите на кнопку Яндекс.Вордстат (1 выделенная зеленым кнопка);
- Просмотрите варианты и выберите подходящие;
- Перенесите подходящие запросы во 2 и 3 кнопки, выделенные зеленым на скрине;
- Получите подходящие ключи.
Сама программа довольно проста в использовании + есть инструкции в интернете. При желании можно купить и пользоваться.
Составляем семантическое ядро своими руками
Подберите вышеуказанными способами подходящие ключевые запросы. Не стоит сразу набирать 2000, можно ограничиться 200 запросами, а потом развивать. Посидите и подумайте, какие ключи можно использовать и составьте полный список. Вам нужно набрать ключи для первой страницы и еще для нескольких статей.
Отсейте слова и запросы, по которым вы не планируете продвигаться. У меня часто попадаются запросы вроде «работа на дому Пермь» или по другим городам, так что их сразу выкидываю. Оценивайте сразу – что хотят получить люди по этому запросу и сможете ли вы это дать?
Убирайте высококонкурентные запросы, по которым вы не сможете пробиться в ТОП10. При возникновении сомнений посмотрите на сайте Мутаген уровень конкуренции. Ну или вручную оценивайте выдачу – популярные запросы видно сразу.
Распределите запросы по сайту. Среднечастотные запросы идут на главную страницу, низкочастотные сгруппируйте по смыслу и используйте в статьях или разделах. Используйте их как ключевые слова в статьях (1 среднечастотный главный, пара низкочастотных в статье и подзаголовках, и разбавьте по тексту вспомогательными). Вписывайте в среднем 1-2 ключа на 2000 знаков, не чаще.
Некоторые не создают СЯ и все равно добиваются успеха. Но лучше знать, как составить семантическое ядро своими руками, программы для подбора слов сделают это практически на автомате (словоеб). А вам будет потом намного проще развиваться и писать статьи.
Семантическое ядро — довольно избитая тема, не так ли? Сегодня мы вместе это исправим, собрав семантику в этом уроке!
Не верите? - посмотрите сами - достаточно просто вбить в Яндекс или Гугл фразу семантическое ядро сайта. Думаю, что сегодня я исправлю эту досадную ошибку.
А ведь и в самом деле, какая она для вас - идеальная семантика ? Можно подумать, что за глупый вопрос, но на самом деле он совсем даже неглуп, просто большинство web-мастеров и владельцев сайтов свято верят, что умеют составлять семантические ядра и в то, что со всем этим справится любой школьник, да еще и сами пытаются научить других… Но на самом деле все намного сложней. Однажды у меня спросили — что стоит делать вначале? — сам сайт и контент или сем ядро , причем спросил человек, который далеко не считает себя новичком в сео. Вот данный вопрос и дал мне понять всю сложность и неоднозначность данной проблемы.
Семантическое ядро — основа основ — тот самый первый шажок, который стоит перед и запуском любой рекламной кампании в интернете. Наряду с этим — семантика сайта наиболее муторный процесс, который потребует немало времени, зато с лихвой окупится в любом случае.
Ну что же… Давайте создадим его вместе!
Небольшое предисловие
Для создания семантического поля сайта нам понадобится одна-единственная программа — Key Collector . На примере Коллектора я разберу пример сбора небольшой сем группы. Помимо платной программы, есть и бесплатные аналоги вроде СловоЕб и других.
Семантика собирается в несколько базовых этапов, среди которых следует выделить:
- мозговой штурм - анализ базовых фраз и подготовка парсинга
- парсинг - расширение базовой семантики на основе Вордстат и других источников
- отсев - отсев после парсинга
- анализ - анализ частотности, сезонности, конкуренции и других важных показателей
- доработка - групировка, разделение коммерческих и информационных фраз ядра
О наиболее важных этапах сбора и пойдет речь ниже!
ВИДЕО - составление семантического ядра по конкурентам
Мозговой штурм при создании семантического ядра — напрягаем мозги
На данном этапе надо в уме произвести подбор семантического ядра сайта и придумать как можно больше фраз под нашу тематику. Итак, запускаем кей коллектор и выбираем парсинг Wordstat , как это показано на скриншоте:

Перед нами открывается маленькое окошко, где необходимо ввести максимум фраз по нашей тематике. Как я уже говорил, в данной статье мы создадим пример набор фраз для этого блога , поэтому фразы могут быть следующими:
- seo блог
- сео блог
- блог про сео
- блог про seo
- продвижение
- продвижение проекта
- раскрутка
- раскрутка
- продвижение блогов
- продвижение блога
- раскрутка блогов
- раскрутка блога
- продвижение статьями
- статейное продвижение
- miralinks
- работа в sape
- покупка ссылок
- закупка ссылок
- оптимизация
- оптимизация страницы
- внутренняя оптимизация
- самостоятельная раскрутка
- как раскрутить ресурс
- как раскрутить свой сайт
- как раскрутить сайт самому
- как раскрутить сайт самостоятельно
- самостоятельная раскрутка
- бесплатная раскрутка
- бесплатное продвижение
- поисковая оптимизация
- как продвинуть сайт в яндексе
- как раскрутить сайт в яндексе
- продвижение под яндекс
- продвижение под гугл
- раскрутка в гугл
- индексация
- ускорение индексации
- выбор донора сайту
- отсев доноров
- раскрутка постовыми
- использование постовых
- раскрутка блогами
- алгоритм яндекса
- апдейт тиц
- апдейт поисковой базы
- апдейт яндекса
- ссылки навсегда
- вечные ссылки
- аренда ссылок
- арендованные ссылке
- ссылки с помесячной оплатой
- составление семантического ядра
- секреты раскрутки
- секреты раскрутки
- тайны seo
- тайны оптимизации
Думаю, достаточно, и так список с пол страницы;) В общем, идея в том, что на первом этапе вам необходимо проанализировать по максимуму свою отрасль и выбрать как можно больше фраз, отражающих тематику сайта. Хотя, если вы что-либо упустили на этом этапе — не отчаивайтесь — упущенные словосочетания обязательно всплывут на следующих этапах , просто придется делать много лишней работы, но ничего страшного. Берем наш список и копируем в key collector. Далее, нажимаем на кнопку — Парсить с Яндекс.Wordstat :
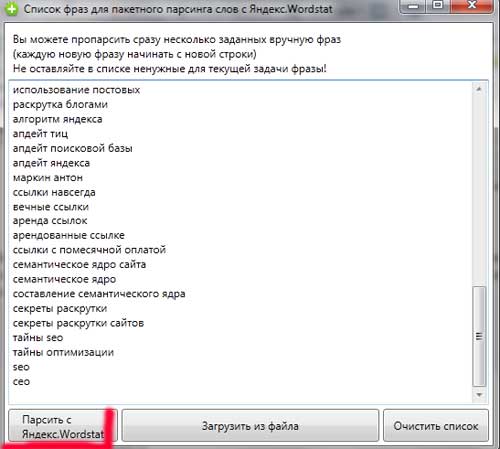
Парсинг может занять довольно продолжительное время, поэтому следует запастись терпением. Семантическое ядро обычно собирается 3-5 дней и первый день у вас уйдет на подготовку базового семантического ядра и парсинг.
О том, как работать с ресурсом , как подобрать ключевые слова я писал подробную инструкцию. А можно узнать о продвижении сайта по НЧ запросам.
Дополнительно скажу, что вместо мозгового штурма мы можем использовать уже готовую семантику конкурентов при помощи одного из специализированных сервисов, например — SpyWords. В интерфейсе данного сервиса мы просто вводим необходимое нам ключевое слово и видим основных конкурентов, которые присутствуют по этому словосочетанию в ТОП. Более того - семантика сайта любого конкурента может быть полностью выгружена при помощи этого сервиса.

Далее, мы можем выбрать любого из них и вытащить его запросы, которую останется отсеять от мусора и использовать как базовую семантику для дальнейшего парсинга. Либо мы можем поступить еще проще и использовать .
Чистка семантики
Как только, парсинг вордстата полностью прекратится — пришло время отсеять семантическое ядро . Данный этап очень важен, поэтому отнеситесь к нему с должным вниманием.
Итак, у меня парсинг закончился, но словосочетаний получилось ОЧЕНЬ много , а следовательно, отсев слов может отнять у нас лишнее время. Поэтому, перед тем как перейти к определению частотности, следует произвести первичную чистку слов. Сделаем мы это в несколько этапов:
1. Отфильтруем запросы с очень низкими частотностями
Для этого наживаем на символ сортировки по частотности, и начинаем отчищать все запросы, у которых частотности ниже 30:
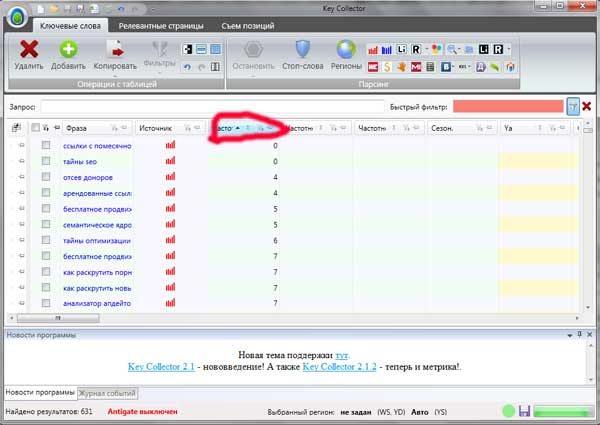
Думаю, что с данным пунктом вы сможете без труда справиться.
2. Уберем не подходящие по смыслу запросы
Существуют такие запросы, которые имеют достаточную частотность и низкую конкуренцию, но они совершенно не подходят под нашу тематику . Такие ключи необходимо удалить перед проверкой точных вхождений ключа, т.к. проверка может отнять очень много времени. Удалять такие ключи мы будем вручную. Итак, для моего блога лишними оказались:
курсы поисковой оптимизации продам раскрученный сайт
Анализ семантического ядра
На данном этапе, нам необходимо определить точные частотности наших ключей, для чего вам необходимо нажать на символ лупы, как это показано на изображении:

Процесс довольно долгий, поэтому можете пойти и приготовить себе чай)
Когда проверка прошла успешно — необходимо продолжить чистку нашего ядра.
Предлагаю вам удалить все ключи с частотностью меньше 10 запросов. Также, для своего блога я удалю все запросы, имеющие значения выше 1 000, так как продвигаться по таким запросам я пока что не планирую.
Экспорт и группировка семантического ядра
Не стоит думать, что данный этап окажется последним. Совсем нет! Сейчас нам необходимо перенести получившуюся группу в Exel для максимальной наглядности. Далее мы будем сортировать по страницам и тогда увидим многие недочеты, исправлением которых и займемся.
Экспортируется семантика сайта в Exel совсем нетрудно. Для этого просто необходимо нажать на соответствующий символ, как это показано на изображении:

После вставки в Exel, мы увидим следующую картину:

Столбцы, помеченные красным цветом необходимо удалить. Затем создаем еще одну таблицу в Exel, где будет содержаться финальное семантическое ядро.
В новой таблице будет 3 столбца: URL страницы , ключевое словосочетание и его частотность . В качестве URL выбираем или уже существующую страницу или страницу, которая будет создана в перспективе. Для начала, давайте выберем ключи для главной страницы моего блога:

После всех манипуляций, мы видим следующую картину. И сразу напрашивается несколько выводов:
- такие частотные запросы, как должны иметь намного больший хвост из менее частотных фраз, чем мы видим
- сео новости
- всплыл новый ключ, который мы не учли ранее — статьи сео . Необходимо проанализировать этот ключ
Как я уже говорил, ни один ключ от нас не спрячется. Следующим шагом для нас станет мозговой штурм этих трех фраз. После мозгового штурма повторяем все шаги начиная с самого первого пункта для этих ключей. Вам может все это показаться слишком долгим и нудным, но так оно и есть — составление семантического ядра — очень ответственная и кропотливая работа. Зато, грамотно составленное сем поле сильно поможет в продвижении сайта и способно сильно сэкономить ваш бюджет.
После всех проделанных операций, мы смогли получить новые ключи для главной страницы этого блога:
- лучший seo блог
- seo новости
- статьи seo
И некоторые другие. Думаю, что методика вам понятна.
После всех этих манипуляций мы увидим, какие страницы нашего проекта необходимо изменить (), а какие новые страницы необходимо добавить. Большинство ключей, найденных нами (с частотностью до 100, а иногда и намного выше) можно без труда продвинуть одними .
Финальный отсев
В принципе, семантическое ядро практически готово, но есть еще один довольно важный пункт, который поможет нам заметно улучшить нашу сем группу. Для этого нам понадобится Seopult.
*На самом деле тут можно использовать любой из аналогичных сервисов, позволяющих узнать конкуренцию по ключевым словам, например, Мутаген!
Итак, создаем еще одну таблицу в Exel и копируем туда только названия ключей (средний столбец). Чтобы не тратить много времени, я скопирую только ключи для главной страницы своего блога:
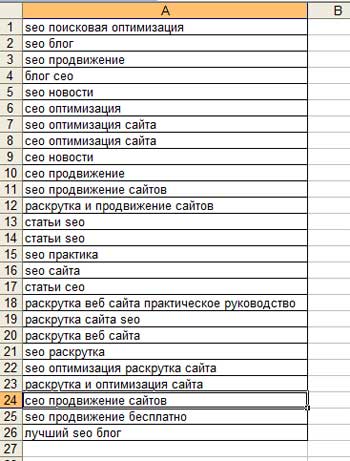

Затем проверяем стоимость получения одного перехода по нашим ключевым словам:

Стоимость перехода по некоторым словосочетаниям превысила 5 рублей. Такие фразы необходимо исключить из нашего ядра.
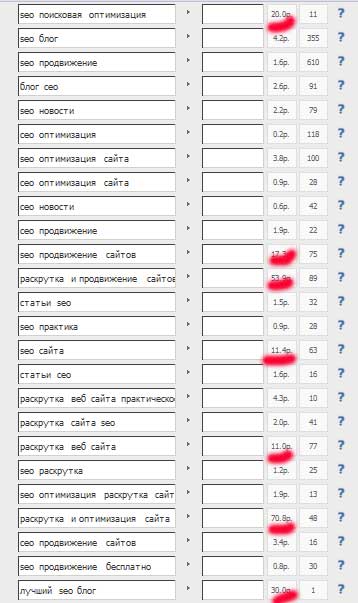
Возможно, ваши предпочтения окажутся несколько иными, тогда вы можете исключать и менее дорогие фразы или наоборот. В своем случае, я удалил 7 фраз .
Полезная информация!
по составлению семантического ядра, с упором на отсев наиболее низкоконкурентных ключевых слов.
Если у вас свой интернет-магазин — прочитайте , где описано, как может быть использовано семантическое ядро.
Кластеризация семантического ядра
Уверен, что ранее тебе уже доводилось слышать это слово применительно к поисковому продвижению. Давай разберемся, что же это за зверь такой и зачем он нужен при продвижении сайта.
Классическая модель поискового продвижения выглядит следующим образом:
- Подбор и анализ поисковых запросов
- Группировка запросов по страницам сайта (создание посадочных страниц)
- Подготовка seo текстов для посадочных страниц на основе группы запросов для этих страниц
Для облегчения и улучшения второго этапа в списке выше и служит кластеризация. По сути своей - кластеризация это программный метод, служащий для упрощения этого этапа при работе с большими семантиками, но тут не все так просто, как может показаться на первый взгляд.
Для лучшего понимания теории кластеризации следует сделать небольшой экскурс в историю SEO:
Еще буквально несколько лет назад, когда термин кластеризация не выглядывал из-за каждого угла - сеошники, в подавляющем большинстве случаев, группировали семантику руками. Но при группировке огромных семантик в 1000, 10 000 и даже 100 000 запросов данная процедура превращалась в настоящую каторгу для обычного человека. И тогда повсеместно начали использовать методику группировки по семантике (и сегодня очень многие используют этот подход). Методика группировки по семантике подразумевает объединение в одну группу запросов, имеющих семантическое родство. Как пример - запросы “купить стиральную машинку” и “купить стиральную машинку до 10 000” объединялись в одну группу. И все бы хорошо, но данный метод содержит в себе целый ряд критических проблем и для их понимания необходимо ввести новый термин в наше повествование, а именно – “интент запроса ”.
Проще всего описать данный термин можно как потребность пользователя, его желание. Интент является ни чем иным, как желанием пользователя, вводящего поисковый запрос.
Основа группировки семантики - собрать в одну группу запросы, имеющие один и тот же интент, либо максимально близкие интенты, причем тут всплывает сразу 2 интересных особенности, а именно:
- Один и тот же интент могут иметь несколько запросов не имеющих какой-либо семантической близости, например – “обслуживание автомобиля” и “записаться на ТО”
- Запросы, имеющие абсолютную семантическую близость могут содержать в себе кардинально разные интенты, например, хрестоматийная ситуация – “мобильник” и “мобильники”. В одном случае пользователь хочет купить телефон, а в другом посмотреть фильм
Так вот, группировка семантики по семантическому соответствию никак не учитывает интенты запросов. И группы, составленные таким образом не позволят написать текст, который попадет в ТОП. Во временя ручной группировки для устранения этого недоразумения ребята с профессией «подручный SEO специалиста» анализировали выдачу руками.
Суть кластеризации – сравнение сформировавшейся выдачи поисковой системы в поисках закономерностей. Из этого определения сразу следует сделать для себя заметку, что сама кластеризация не является истиной в последней инстанции, ведь сформировавшаяся выдача может и не раскрывать полностью интент (в базе Яндекс может просто не быть сайта, который правильно объединил запросы в группу).
Механика кластеризации проста и выглядит следующим образом:
- Система поочередно вводит все поданные ей запросы в поисковую выдачу и запоминает результаты из ТОП
- После поочередного ввода запросов и сохранения результатов, система ищет пересечения в выдаче. Если один и тот же сайт одним и тем же документом (страница сайта) находится в ТОП сразу по нескольким запросам, то эти запросы теоретически можно объединить в одну группу
- Становится актуальным такой параметр, как сила группировки, который говорит системе, сколько именно должно быть пересечений, чтобы запросы можно было добавить в одну группу. К примеру, сила группировки 2 означает, что в выдаче по 2-м разным запросам должно присутствовать не менее двух пересечений. Говоря еще проще – минимум две страницы двух разных сайтов должны присутствовать одновременно в ТОП по одному и другому запросу. Пример ниже.
- При группировках больших семантики становится актуальна логика связей между запросами, на основе которой выделяют 3 базовых вида кластеризации: soft, middle и hard. О видах кластеризации мы еще поговорим в следующих записях этого дневника

Семантическое ядро сайта – это полный набор ключевых слов, соответствующих тематике веб-ресурса, по которым пользователи смогут найти его в поисковой системе.
Больше видео на нашем канале - изучайте интернет-маркетинг с SEMANTICA
![]()
К примеру, сказочный персонаж баба Яга будет иметь следующее семантическое ядро: баба Яга, баба Яга сказки, баба Яга русские сказки, баба со ступой сказки, баба со ступой и метлой, злая баба волшебница, баба избушка курьи ножки и т.д.
Для чего сайту семантическое ядро
Перед началом работ по продвижению вам необходимо найти все ключи, по которым его могут искать целевые посетители. На основании семантики составляется структура, распределяются ключи, прописываются метатеги, заголовки документов, описания к изображениям, а также разрабатывается анкор-лист для работы со ссылочной массой.
При составлении семантики необходимо решить главную проблему: определить, какую информацию следует опубликовать, чтобы привлечь потенциального клиента.
Составление списка ключей решает еще одну важную задачу: для каждой поисковой фразы вы определяете релевантную страницу, которая полно сможет ответить на вопрос пользователя.
Данная задача решается двумя путями:
- Вы создаете структуру сайта на основе семантического ядра.
- Вы распределяете подобранные термины по готовой структуре ресурса.
Виды ключевых запросов (КЗ) по количеству просмотров
- НЧ – низкочастотные. До 100 показов в месяц.
- СЧ – среднечастотные. От 101 до 1 000 показов.
- ВЧ – высокочастотные. Более 1000 показов.
По статистике, 60-80% всех фраз и слов относятся к НЧ. Работать при продвижении с ними дешевле и проще. Поэтому вы должны составить максимально объемное ядро фраз, которое будет постоянно дополняться новыми НЧ. ВЧ и СЧ также не стоит игнорировать, но основной упор делайте на расширение списка низкочастотников.
Виды КЗ по типу поиска
- Информационные нужны при поиске информации. «Как жарить картофель» или «сколько звезд на небе».
- Транзакционные используются для совершения действия. «Заказать пуховый платок», «скачать песни Высоцкого»
- Навигационные используются для поиска связанного с какой-то конкретной фирмой или привязкой к сайту. «Хлебопечь МВидео» или «смартфоны Связной».
- Прочие - расширенный список, по которому невозможно понять конечную цель поиска. К примеру, запрос «торт Наполеон» – возможно, человек ищет рецепт его приготовления, а, возможно, хочет купить торт.
Как составить семантику
Необходимо выделить главные термины вашего бизнеса и нужд пользователей. К примеру, клиенты прачечной интересуются стиркой и чисткой.
Затем следует определить хвосты и спецификацию (более 2 слов в запросе), которые пользователи добавляют к главным терминам. Этим вы увеличите охват целевой аудитории и снизите частотность терминов (стирка пледов, стирка курток и т.п.).
Сбор семантического ядра вручную
Яндекс Wordstat
- Выберите регион веб-ресурса.
- Введите ключевую фразу. Сервис выдаст вам количество запросов с данным ключевиком за последний месяц и список «родственных» терминов, которые интересовали посетителей. Имейте ввиду, что если вы вводите, к примеру, «купить окна», то получаете результаты по точному вхождению ключевика. Если вводите данный ключ без кавычек, то получаете общие результаты, и запросы типа «купить окна в воронеже» и «купить окно пластиковое» также будут отражены в данной цифре. Для сужения и уточнения показателя можно воспользоваться оператором «!», который ставится перед каждым словом: !купить!окна. Вы получите число, показывающее точную выдачу по каждому слову. Получится список типа: купить пластиковые окна, купить и заказать окна, при этом слова «купить» и «окна» будут отражаться в неизменном виде. Для получения абсолютного показателя по запросу «купить окна» следует применять следующую схему: вводим в кавычках «!купить!окна». Вы получите самые точные данные.
- Соберите слова из левой колонки и проанализируйте каждое из них. Составьте начальную семантику. Обращайте внимание на правую колонку, содержащую КЗ, которые пользователи вводили до или после поиска слов из левой колонки. Вы найдете еще немало нужных фраз.
- Пройдите по вкладке «История запросов». На графике вы сможете проанализировать сезонность, популярность фраз в каждом месяце. Неплохие результаты дает работа с поисковыми подсказками Яндекса. Каждый КЗ вводится в поисковое поле, и на основе всплывающих подсказок расширяется семантика.
Google-планировщик КЗ
- Введите главный ВЧ запрос.
- Выберите «Получить варианты».
- Отберите самые релевантные варианты.
- Повторите данной действие с каждой отобранной фразой.
Изучение сайтов-конкурентов
Используйте этот метод как дополнительный, чтобы определить правильность выбора того или иного КЗ. В этом вам помогут инструменты BuzzSumo, Searchmetrics, SEMRush, Адвсе.
Программы для составления семантического ядра
Рассмотрим некоторые самые популярные сервисы.
- Key Collector. Если вы составляете очень объемную семантику, то без этого инструмента вам не обойтись. Программа подбирает семантику, обращаясь к Яндекс Wordstat, собирает поисковые подсказки данного поисковика, фильтрует КЗ со стоп-словами, очень низкой частотой, дублированные, определяет сезонность фраз, изучает статистику счетчиков и соцсетей, подбирает релевантные страницы к каждому запросу.
- SlovoEB. Бесплатный сервис от Key Collector. Инструмент подбирает ключевые слова, группирует и анализирует их.
- Allsubmitter. Помогает подобрать КЗ, показывает сайты-конкуренты.
- KeySO. Анализирует видимость веб-ресурса, его конкурентов и помогает в составлении СЯ.
Что нужно учитывать при подборе ключевых фраз
- Показатели частотности.
- Большая часть КЗ должна быть НЧ, остальные - СЧ и ВЧ.
- Релевантные поисковым запросам страницы.
- Конкурентов в ТОП.
- Конкурентность фразы.
- Прогнозируемое количество переходов.
- Сезонность и геозависимость.
- КЗ с ошибками.
- Ассоциативные ключи.
Правильное семантическое ядро
Прежде всего, необходимо определиться с понятиями «ключевые слова», «ключи», «ключевые или поисковые запросы» – это слова или фразы, при помощи которых потенциальные клиенты вашего сайта ищут необходимую информацию.
Составьте следующие списки: категории товаров или услуг (далее -ТУ), названия ТУ их бренды, коммерческие хвосты («купить», «заказать» и т.п.), синонимы, транслитерацию на латинице (или на русском соответственно), профессиональные жаргонизмы («клавиатура» – «клава» и т.п.), технические характеристики, слова с возможными опечатками и ошибками («оренбуржский» вместо «оренбургский» и т.п.), привязки к местности (город, улицы и т.п.).
При работе со списками ориентируйтесь на КЗ из договора по продвижению, структуру веб-ресурса, информацию, прайс-листы, сайты-конкуренты, опыт предшествующего SEO.
Приступайте к подбору семантики путем смешения выбранных на предыдущем шаге словосочетаний, используя ручной метод или при помощи сервисов.
Сформируйте список стоп-слов и удалите неподходящие КЗ.
Сгруппируйте КЗ по релевантным страницам. Под каждый ключ подбирается наиболее релевантная страница или создается новый документ. Желательно данную работу проводить вручную. Для крупных проектов предусмотрены платные сервисы типа Rush Analytics.
Идите от большего к меньшему. Сначала распределите ВЧ по страницам. Затем то же самое проделайте с СЧ. НЧ можно добавить к страницам с распределенными по ним ВЧ и НЧ, а также подобрать для них индивидуальные страницы.
После анализа первых результатов работ мы можем увидеть, что:
- продвигаемый сайт не виден по всем заявленным ключевым словам;
- по КЗ выдаются не те документы, которые вы предполагали релевантными;
- мешает неправильная структура веб-ресурса;
- для некоторых КЗ релевантны несколько веб-страниц;
- не хватает релевантных страниц.
При группировке КЗ работайте со всеми возможными разделами на веб-ресурсе, наполняйте каждую страницу полезной информацией, не создавайте дублированный текст.
Распространенные ошибки при работе с КЗ
- была подобрана только очевидная семантика, без словоформ, синонимов и т.д;
- оптимизатор распределил слишком много КЗ на одну страницу;
- одинаковые КЗ распределены на разные страницы.
При этом ранжирование ухудшается, сайт может быть наказан за переспам, а если у веб-ресурса неправильная структура, то продвигать его будет очень сложно.
Не важно, каким образом вы будете подбирать семантику. При правильном подходе вы получите правильное СЯ, необходимое для успешного продвижения сайта.
Здравствуйте, уважаемые читатели блога сайт. Хочу сделать очередной заход на тему «сбора семядра». Сначала , как полагается, а потом много практики, может быть и несколько неуклюжей в моем исполнении. Итак, лирика. Ходить с завязанными глазами в поисках удачи мне надоело уже через год, после начала ведения этого блога. Да, были «удачные попадания» (интуитивное угадывание часто задаваемых поисковикам запросов) и был определенный трафик с поисковиков, но хотелось каждый раз бить в цель (по крайней мере, ее видеть).
Потом захотелось большего — автоматизации процесса сбора запросов и отсева «пустышек». По этой причине появился опыт работы с Кейколлектором (и его неблагозвучным младшим братом) и очередная статья на тему . Все было здорово и даже просто замечательно, пока я не понял, что есть один таки очень важный момент, оставшийся по сути за кадром — раскидывание запросов по статьям.
Писать отдельную статью под отдельный запрос оправдано либо в высококонкурентных тематиках, либо в сильно доходных. Для инфосайтов же — это полный бред, а посему приходится запросы объединять на одной странице. Как? Интуитивно, т.е. опять же вслепую. А ведь далеко не все запросы уживаются на одной странице и имеют хотя бы гипотетический шанс выйти в Топ.
Собственно, сегодня как раз и пойдет речь об автоматической кластеризации семантического ядра посредством KeyAssort (разбивке запросов по страницам, а для новых сайтов еще и построение на их основе структуры, т.е. разделов, категорий). Ну, и сам процесс сбора запросов мы еще раз пройдем на всякий пожарный (в том числе и с новыми инструментами).
Какой из этапов сбора семантического ядра самый важный?
Сам по себе сбор запросов (основы семантического ядра) для будущего или уже существующего сайта является процессом довольно таки интересным (кому как, конечно же) и реализован может быть несколькими способами, результаты которых можно будет потом объединить в один большой список (почистив дубли, удалив пустышки по стоп словам).
Например, можно вручную начать терзать Вордстат , а в добавок к этому подключить Кейколлектор (или его неблагозвучную бесплатную версию). Однако, это все здорово, когда вы с тематикой более-менее знакомы и знаете ключи, на которые можно опереться (собирая их производные и схожие запросы из правой колонки Вордстата).
В противном же случае (да, и в любом случае это не помешает) начать можно будет с инструментов «грубого помола». Например, Serpstat (в девичестве Prodvigator), который позволяет буквально «ограбить» ваших конкурентов на предмет используемых ими ключевых слов (смотрите ). Есть и другие подобные «грабящие конкурентов» сервисы (spywords, keys.so), но я «прикипел» именно к бывшему Продвигатору.
В конце концов, есть и бесплатный Букварис , который позволяет очень быстро стартануть в сборе запросов. Также можно заказать частным образом выгрузку из монстрообразной базы Ahrefs и получить опять таки ключи ваших конкурентов. Вообще, стоит рассматривать все, что может принести хотя бы толику полезных для будущего продвижения запросов, которые потом не так уж сложно будет почистить и объединить в один большой (зачастую даже огромный список).
Все это мы (в общих чертах, конечно же) рассмотрим чуть ниже, но в конце всегда встает главный вопрос — что делать дальше . На самом деле, страшно бывает даже просто подступиться к тому, что мы получили в результате (пограбив десяток-другой конкурентов и поскребя по сусекам Кейколлектором). Голова может лопнуть от попытки разбить все эти запросы (ключевые слова) по отдельным страницах будущего или уже существующего сайта.
Какие запросы будут удачно уживаться на одной странице, а какие даже не стоит пытаться объединять? Реально сложный вопрос, который я ранее решал чисто интуитивно, ибо анализировать выдачу Яндекса (или Гугла) на предмет «а как там у конкурентов» вручную убого, а варианты автоматизации под руку не попадались. Ну, до поры до времени. Все ж таки подобный инструмент «всплыл» и о нем сегодня пойдет речь в заключительной части статьи.
Это не онлайн-сервис, а программное решение, дистрибутив которого можно скачать на главной странице официального сайта (демо-версию).

Посему никаких ограничений на количество обрабатываемых запросов нет — сколько надо, столько и обрабатывайте (есть, однако, нюансы в сборе данных). Платная версия стоит менее двух тысяч, что для решаемых задач, можно сказать, даром (имхо).
Но про техническую сторону KeyAssort мы чуть ниже поговорим, а тут хотелось бы сказать про сам принцип, который позволяет разбить список ключевых слов (практически любой длины) на кластеры, т.е. набор ключевых слов, которые с успехом можно использовать на одной странице сайта (оптимизировать под них текст, заголовки и ссылочную массу — применить магию SEO).
Откуда вообще можно черпать информацию? Кто подскажет, что «выгорит», а что достоверно не сработает? Очевидно, что лучшим советчиком будет сама поисковая система (в нашем случае Яндекс, как кладезь коммерческих запросов). Достаточно посмотреть на большом объеме данных выдачу (допустим, проаналазировать ТОП 10) по всем этим запросам (из собранного списка будущего семядра) и понять, что удалось вашим конкурентам успешно объединить на одной странице. Если эта тенденция будет несколько раз повторяться, то можно говорить о закономерности, а на основе нее уже можно бить ключи на кластеры.
KeyAssort позволяет в настройках задавать «строгость», с которой будут формироваться кластеры (отбирать ключи, которые можно использовать на одной странице). Например, для коммерции имеет смысл ужесточать требования отбора, ибо важно получить гарантированный результат, пусть и за счет чуть больших затрат на написание текстов под большее число кластеров. Для информационных сайтов можно наоборот сделать некоторые послабления, чтобы меньшими усилиями получить потенциально больший трафик (с несколько большим риском «невыгорания»). Как это сделать опять же поговорим.
А что делать, если у вас уже есть сайт с кучей статей, но вы хотите расширить существующее семядро и оптимизировать уже имеющиеся статьи под большее число ключей, чтобы за минимум усилий (чуток сместить акцент ключей) получить поболе трафика? Эта программка и на этот вопрос дает ответ — можно те запросы, под которые уже оптимизированы существующие страницы, сделать маркерными, и вокруг них KeyAssort соберет кластер с дополнительными запросами, которые вполне успешно продвигают (на одной странице) ваши конкуренты по выдаче. Интересненько так получается...
Как собрать пул запросов по нужной вам тематике?
Любое семантическое ядро начинается, по сути, со сбора огромного количества запросов, большая часть из которых будет отброшена. Но главное, чтобы на первичном этапе в него попали те самые «жемчужины», под которые потом и будут создаваться и продвигаться отдельные страницы вашего будущего или уже существующего сайта. На данном этапе, наверное, самым важным является набрать как можно больше более-менее подходящих запросов и ничего не упустить, а пустышки потом легко отсеяться.
Встает справедливый вопрос, а какие инструменты для этого использовать ? Есть один однозначный и очень правильный ответ — разные. Чем больше, тем лучше. Однако, эти самые методики сбора семантического ядра, наверное, стоит перечислить и дать общие оценки и рекомендации по их использованию.
- Яндекс Вордстат
и его аналоги у других поисковых систем — изначально эти инструменты предназначались для тех, кто размещает контекстную рекламу, чтобы они могли понимать, насколько популярны те или иные фразы у пользователей поисковиков. Ну, понятно, что Сеошники этими инструментами пользуются тоже и весьма успешно. Могу порекомендовать пробежаться глазами по статье , а также упомянутой в самом начале этой публикации статье (полезно будет начинающим).

Из недостатков Водстата можно отметить:
- Чудовищно много ручной работы (однозначно требуется автоматизация и она будет рассмотрена чуть ниже), как по пробивке фраз основанных на ключе, так и по пробивке ассоциативных запросов из правой колонки.
- Ограничение выдачи Вордстата (2000 запросов и не строчкой больше) может стать проблемой, ибо для некоторых фраз (например, «работа») это крайне мало и мы упускаем из вида низкочастотные, а иногда даже и среднечастотные запросы, способные приносить неплохой трафик и доход (их ведь многие упускают). Приходится «сильно напрягать голову», либо использовать альтернативные методы (например, базы ключевых слов, одну из которых мы рассмотрим ниже — при этом она бесплатная!).
- КейКоллектор
(и его бесплатный младший брат Slovoeb
) — несколько лет назад появление этой программы было просто «спасением» для многих тружеников сети (да и сейчас представить без КК работу над семядром довольно трудно). Лирика. Я купил КК еще два или три года назад, но пользовался им от силы несколько месяцев, ибо программа привязана к железу (начинке компа), а она у меня по нескольку раз в год меняется. В общем, имея лицензию на КК пользуюсь SE — так то вот, до чего лень доводит.

Подробности можете почитать в статье « ». Обе программы помогут вам собрать запросы и из правой, и из левой колонки Вордстата, а также поисковые подсказки по нужным вам ключевым фразам. Подсказки — это то, что выпадает из поисковой строки, когда вы начинаете набирать запрос. Пользователи часто не закончив набор просто выбирают наиболее подходящий из этого списка вариант. Сеошники это дело просекли и используют такие запросы в оптимизации и даже .
КК и SE позволяют сразу набрать очень большой пул запросов (правда, может потребоваться много времени, либо покупка XML лимитов, но об этом чуть ниже) и легко отсеять пустышки, например, проверкой частотности фраз взятых в кавычки (учите матчасть, если не поняли о чем речь — ссылки в начале публикации) или задав список стоп-слов (особо актуально для коммерции). После чего весь пул запросов можно легко экспортировать в Эксель для дальнейшей работы или для загрузки в KeyAssort (кластеризатор), о котором речь пойдет ниже.
- СерпСтат
(и другие подобные сервисы) — позволяет введя Урл своего сайта получить список ваших конкурентов по выдаче Яндекса и Гугла. А по каждому из этих конкурентов можно будет получить полный список ключевых слов, по которым им удалось пробиться и достичь определенных высот (получить трафик с поисковиков). Сводная таблица будет содержать частотность фразы, место сайта по ней в Топе и кучу другой разной полезной и не очень информации.

Не так давно я пользовал почти самый дорогой тарифный план Серпстата (но только один месяц) и успел за это время насохранять в Экселе чуть ли не гигабайт разных полезняшек. Собрал не только ключи конкурентов, но и просто пулы запросов по интересовавшим меня ключевым фразам, а также собрал семядра самых удачных страниц своих конкурентов, что, мне кажется, тоже очень важно. Одно плохо — теперь никак время не найду, чтобы вплотную заняться обработкой всей это бесценной информации. Но возможно, что KeyAssort все-таки снимет оцепенение перед чудовищной махиной данных, которые нужно обработать.
- Букварикс
— бесплатная база ключевых слов в своей собственной программной оболочке. Подбор ключевиков занимает доли секунды (выгрузка в Эксель минуты). Сколько там миллионов слов не помню, но отзывы о ней (в том числе и мой) просто отличные, и главное все это богатство бесплатно! Правда, дистрибутив программы весить 28 Гигов, а в распокованном виде база занимает на жестком диске более 100 Гбайт, но это все мелочи по сравнению с простотой и скоростью сбора пула запросов.

Но не только скорость сбора семядра является основным плюсом по сравнению с Вордстатом и КейКоллектором. Главное, что тут нет ограничений на 2000 строк для каждого запроса, а значит никакие НЧ и сверх НЧ от нас не ускользнут. Конечно же, частотность можно будет еще раз уточнить через тот же КК и по стоп-словам в нем отсев провести, но основную задачу Букварикс выполняет замечательно. Правда, сортировка по столбцам у него не работает, но сохранив пул запросов в Эксель там можно будет сортировать как заблагороссудится.
Наверное, еще как минимум несколько «серьезных» инструментов собора пула запросов приведете вы сами в комментариях, а я их успешно позаимствую...
Как очистить собранные поисковые запросы от «пустышек» и «мусора»?
Полученный в результате описанных выше манипуляций список, скорее всего, будет весьма большим (если не огромным). Поэтому прежде чем загружать его в кластерезатор (у нас это будет KeyAssort) имеет смысл его слегка почистить . Для этого пул запросов, например, можно выгрузить к кейколлектор и убрать:
- Запросы со слишком низкой частотностью (лично я пробиваю частотность в кавычках, но без восклицательных знаков). Какой порог выбирать решать вам, и во многом это зависит от тематики, конкурентности и типа ресурса, под который собирается семядро.
- Для коммерческих запросов имеется смысл использовать список стоп-слов (типа, «бесплатно», «скачать», «реферат», а также, например, названия городов, года и т.п.), чтобы заранее убрать из семядра то, что заведомо не приведет на сайт целевых покупателей (отсеять халявшиков, ищущих информацию, а не товар, ну, и жителей других регионов, например).
- Иногда имеет смысл руководствоваться при отсеве показателем конкуренции по данному запросу в выдаче. Например, по запросу «пластиковые окна» или «кондиционеры» можно даже не рыпаться — провал обеспечен заранее и со стопроцентной гарантией.
Скажите, что это слишком просто на словах, но сложно на деле. А вот и нет. Почему? А потому что один уважаемый мною человек (Михаил Шакин) не пожалел времени и записал видео с подробным описанием способов очистки поисковых запросов в Key Collector :
Спасибо ему за это, ибо данные вопрос гораздо проще и понятнее показать, чем описать в статье. В общем справитесь, ибо я в вас верю...
Настройка кластеризатора семядра KeyAssort под ваш сайт
Собственно, начинается самое интересное. Теперь весь этот огромный список ключей нужно будет как-то разбить (раскидать) на отдельных страницах вашего будущего или уже существующего сайта (который вы хотите существенно улучшить в плане приносимого с поисковых систем трафика). Не буду повторяться и говорить о принципах и сложности данного процесса, ибо зачем тогда я первую часть этой стать писал.
Итак, наш метод довольно прост. Идем на официальный сайт KeyAssort и скачиваем демо-версию , чтобы попробовать программу на зуб (отличие демо от полной версии — это невозможность выгрузить, то бишь экспортировать собранное семядро), а уже опосля можно будет и оплатить (1900 рубликов — мало, мало по современным реалиям). Если хотите сразу начать работу над ядром что называется «на чистовик», то лучше тогда выбрать полную версию с возможностью экспорта.
Программа КейАссорт сама собирать ключи не умеет (это, собственно, и не ее прерогатива), а посему их потребуется в нее загрузить. Сделать это можно четырьмя способами — вручную (наверное, имеется смысл прибегать к этому методу для добавления каких-то найденных уже опосля основного сбора ключей), а также три пакетных способа импорта ключей :
- в формате тхт — когда нужно импортировать просто список ключей (каждый на отдельной строке тхт файлика и ).
- а также два варианта экселевского формата: с нужными вам в дальнейшем параметрами, либо с собранными сайтами из ТОП10 по каждому ключу. Последнее может ускорить процесс кластеризации, ибо программе KeyAssort не придется самой парсить выдачу для сбора эти данных. Однако, Урлы из ТОП10 должны быть свежими и точными (такой вариант списка можно получить, например, в Кейколлекторе).
Да, что я вам рассказываю — лучше один раз увидеть:
В любом случае, сначала не забудьте создать новый проект в том же самом меню «Файл», а уже потом только станет доступной функция импорта:

Давайте пробежимся по настройкам программы (благо их совсем немного), ибо для разных типов сайтов может оказаться оптимальным разный набор настроек. Открываете вкладку «Сервис» — «Настройки программы» и можно сразу переходить на вкладку «Кластеризация» :

Тут самое важное — это, пожалуй, выбор необходимого вам вида кластеризации . В программе могут использоваться два принципа, по которым запросы объединяются в группы (кластеры) — жесткий и мягкий.
- Hard — все запросы попавшие в одну группу (пригодные для продвижения на одной странице) должны быть объединены на одной странице у необходимого числа конкурентов из Топа (это число задается в строке «сила группировки»).
- Soft — все запросы попавшие в одну группу будут частично встречаться на одной странице у нужного числа конкурентов и Топа (это число тоже задается в строке «сила группировки»).
Есть хорошая картинка наглядно все это иллюстрирующая:

Если непонятно, то не берите в голову, ибо это просто объяснение принципа, а нам важна не теория, а практика, которая гласит, что:
- Hard кластеризацию лучше применять для коммерческих сайтов . Этот метод дает высокую точность, благодаря чему вероятность попадания в Топ объединенных на одной странице сайта запросов будет выше (при должном подходе к оптимизации текста и его продвижению), хотя самих запросов будет меньше в кластере, а значит самих кластеров больше (больше придется страниц создавать и продвигать).
- Soft кластеризацию имеет смысл использовать для информационных сайтов , ибо статьи будут получаться с высоким показателем полноты (будут способны дать ответ на ряд схожих по смыслу запросов пользователей), которая тоже учитывается в ранжировании. Да и самих страниц будет поменьше.
Еще одной важной, на мой взгляд, настройкой является галочка в поле «Использовать маркерные фразы» . Зачем это может понадобиться? Давайте посмотрим.
Допустим, что у вас уже есть сайт, но страницы на нем были оптимизированы не под пул запросов, а под какой-то один, или же этот пул вы считаете недостаточно объемным. При этом вы всем сердцем хотите расширить семядро не только за счет добавления новых страниц, но и за счет совершенствования уже существующих (это все же проще в плане реализации). Значит нужно для каждой такой страниц добрать семядро «до полного».
Именно для этого и нужна эта настройка. После ее активации напротив каждой фразы в вашем списке запросов можно будет поставить галочку. Вам останется только отыскать те основные запросы, под которые вы уже оптимизировали существующие страницы своего сайта (по одному на страницу) и программа KeyAssort выстроит кластеры именно вокруг них. Собственно, все. Подробнее в этом видео:
Еще одна важная (для правильной работы программы) настройка живет на вкладке «Сбор данных с Яндекс XML» . вы можете прочитать в приведенной статье. Если вкратце, то Сеошники постоянно парсят выдачу Яндекса и выдачу Вордстата, создавая чрезмерную нагрузку на его мощности. Для защиты была внедрена капча, а также разработан спецдоступ по XML, где уже не будет вылезать капча и не будет происходить искажение данных по проверяемым ключам. Правда, число таких проверок в сутки будет строго ограничено.
От чего зависит число выделенных лимитов? От того, как Яндекс оценит ваши . можно перейдя по этой ссылке (находясь в том же браузере, где вы авторизованы в Я.Вебмастере). Например, у меня это выглядит так:

Там еще есть снизу график распределения лимитов по времени суток, что тоже важно. Если запросов нужно пробить много, а лимитов мало, то не проблема. Их можно докупить . Не у Яндекса, конечно же, напрямую, а у тех, у кого эти лимиты есть, но они им не нужны.
Механизм Яндекс XML позволяет проводить передачу лимитов, а биржи, подвязавшиеся быть посредниками, помогают все это автоматизировать. Например, на XMLProxy можно прикупить лимитов всего лишь по 5 рублей за 1000 запросов, что, согласитесь, совсем уж не дорого.
Но не суть важно, ибо купленные вами лимиты все равно ведь перетекут к вам на «счет», а вот чтобы их использовать в KeyAssort, нужно будет перейти на вкладку "Настройка " и скопировать длинную ссылку в поле «URL для запросов» (не забудьте кликнуть по «Ваш текущий IP» и нажать на кнопку «Сохранить», чтобы привязать ключ к вашему компу):

После чего останется только вставить этот Урл в окно с настройками KeyAssort в поле «Урл для запросов»:

Собственно все, с настройками KeyAssort покончено — можно приступать к кластеризации семантического ядра.
Кластеризация ключевых фраз в KeyAssort
Итак, надеюсь, что вы все настроили (выбрали нужный тип кластеризации, подключили свои или покупные лимиты от Яндекс XML), разобрались со способами импорта списка с запросами, ну и успешно все это дело перенесли в КейАссорт. Что дальше? А дальше уж точно самое интересное — запуск сбора данных (Урлов сайтов из Топ10 по каждому запросу) и последующая кластеризация всего списка на основе этих данных и сделанных вами настроек.
Итак, для начала жмем на кнопку «Собрать данные» и ожидаем от нескольких минут до нескольких часов, пока программа прошерстит Топы по всем запросам из списка (чем их больше, тем дольше ждать):

У меня на три сотни запросов (это маленькое ядро для серии статей про работу в интернете) ушло около минуты. После чего можно уже приступать непосредственно к кластеризации , становится доступна одноименная кнопка на панели инструментов KeyAssort. Процесс этот очень быстрый, и буквально через несколько секунд я получил целый набор калстеров (групп), оформленных в виде вложенных списков:

Подробнее об использовании интерфейса программы, а также про создание кластеров для уже существующих страниц сайта смотрите лучше в ролике, ибо так гораздо нагляднее:
Все, что хотели, то мы и получили, и заметьте — на полном автомате. Лепота.
Хотя, если вы создаете новый сайт, то кроме кластеризации очень важно бывает наметить будущую структуру сайта (определить разделы/категории и распределить по ним кластеры для будущих страниц). Как ни странно, но это вполне удобно делать именно в KeyAssort, но правда уже не в автоматическом режиме, а в ручном режиме. Как?
Проще опять же будет один раз увидеть — все верстается буквально на глазах простым перетаскиванием кластеров из левого окна программы в правое:
Если программу вы таки купили, то сможете экспортировать полученное семантическое ядро (а фактически структуру будущего сайта) в Эксель. Причем, на первой вкладке с запросами можно будет работать в виде единого списка, а на второй уже будет сохранена та структура, что вы настроили в KeyAssort. Весьма, весьма удобно.
Ну, как бы все. Готов обсудить и услышать ваше мнение по поводу сбора семядра для сайта.
Удачи вам! До скорых встреч на страницах блога сайт
Вам может быть интересно
Vpodskazke - новый сервис Вподсказке для продвижения подсказок в поисковых системах
SE Ranking - лучший сервис мониторинга позиций для новичков и профессионалов в SEO
Сбор полного семантического ядра в Топвизоре, многообразие способов подбора ключевых слов и их группировка по страницам
Практика сбора семантического ядра под SEO от профессионала - как это происходит в текущих реалиях 2018
Оптимизация поведенческих факторов без их накрутки
SEO PowerSuite - программы для внутренней (WebSite Auditor, Rank Tracker) и внешней (SEO SpyGlass, LinkAssistant) оптимизации сайта
 SERPClick: продвижение поведенческими факторами
SERPClick: продвижение поведенческими факторами
